原创文档,转载请将原文url地址标明
hadoop 相关视频下载地址: http://pan.baidu.com/share/link?shareid=223046310&uk=3073578852
Hadoop是分布式的网络系统,网络环境是hadoop必备环境。尽管hadoop的演示程序或者默认配置是工作在没有网络环境的单机系统下,但那个配置仅仅是为演示某些概念或者特定的调试程序等使用,对于我们向好好研究hadoop系统而言就是比较简单了,我们时间工作工作可以有很多形式组成网络环境来进行hadoop的研究。为了方便起见我们通过vmware虚拟机搭建一个有3个节点的虚拟网络环境,通过这个环境我们可以方便研究hadoop系统。本文是hadoop系统文章的一部分,下面是系列文章的介绍:
系列文章简介,hadoop代表一种新的编程思想,基于hadoop有很多衍生项目,充分利用他们是非常必要的,同时hadoop又是一个复杂系统,若能理解他的工作原理对我们将有非常大的帮助,我们以hadoop 0.1.0版本为基础逐步分析他的基本工作原理、结构、思路等等,本文是系统文章的一部分,系列文章详情参见
http://www.iigrowing.cn/hadoop_src_introduction
希望通过这个能帮助我们理解生产中hadoop。 时间有限,经验不足,疏漏难免,在这里仅分享一些心得,希望对大家能起到一个抛砖引玉的作用,有问题请大家给我留言或者评论等,这样也能对我的工作有很大帮助。感谢您阅读这篇文章!
一.虚拟机网络设置
我们学习hadoop就需要学习明白hadoop的真正原理,这样我们才能更好利用它,因此一个合适的网络环境对我们是必须的。一个网络环境我们可以有很多选择,可以在局域网内找几台linux服务器等。
最简单的办法是采用vmware搭建三个linux服务器系统。让三台系统可以相互访问
如前一篇文章,我们已经创建了3台虚拟机u01,u02,u03。本文重点介绍虚拟机的网络配置。
1. 三台虚拟机需要在同一个虚拟机环境中运行,或者说在同一个pc机上运行
2. 三台虚拟机需要默认采用nat的网络设置
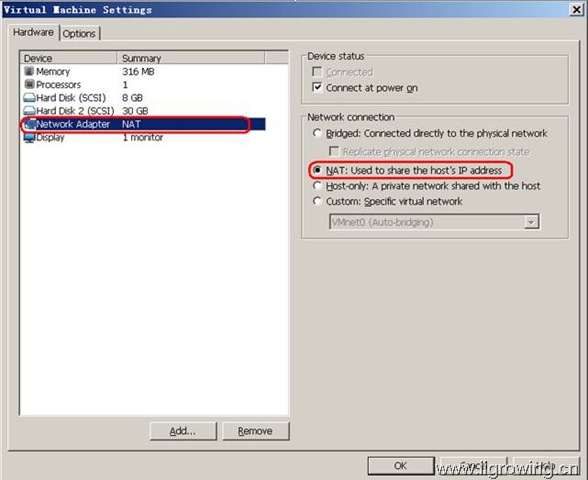
虚拟机网络配置图
这个方式的网络配置,一是可以不占用公司内部局域网的ip地址,又可以保证虚拟机可以正常访问互联网(本次的系列文章中,虚拟机都不需要访问互联网,但是如上需要从网络下载一些资料等,有可能需要)。
我们三台虚拟机都需要采用如上的配置,这样可以保证3台虚拟机都可以相互访问(当然大家可以采用另外配置方式但是要保证网络连通,并且能及时通信等等)。
二.Linux环境中网络设置
默认的虚拟机中网络是采用DHCP方式动态获取的ip地址等。在这种方式下,系统在运行一段时间后,当ip地址租赁期过去后,ip地址有可能会发生更改,因此服务器ip地址有可能发生变化,因此我们采用手动配置ip地址的办法。
(具体操作过程,参见 虚拟机参考配置视频
hadoop-vmware-0.1.0-www.iigrowing.cn.mp4 (37.77M, 2012年11月28日 17:10 到期)
)
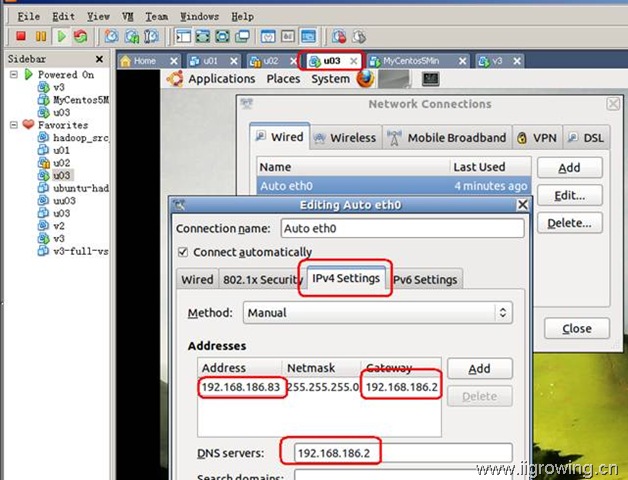
如上图,相关配置
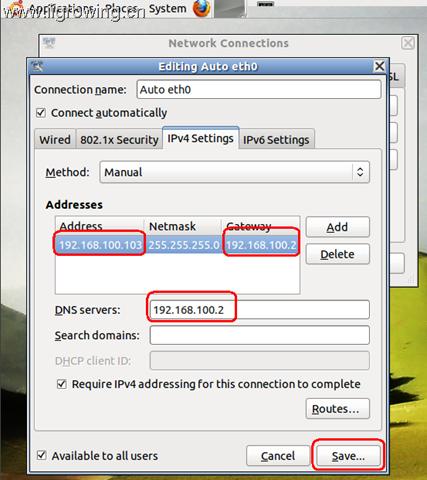
最后配置成如上 情况。
最后,打开一个linux的终端窗口,然后输入
cat /etc/hosts
显示如下信息
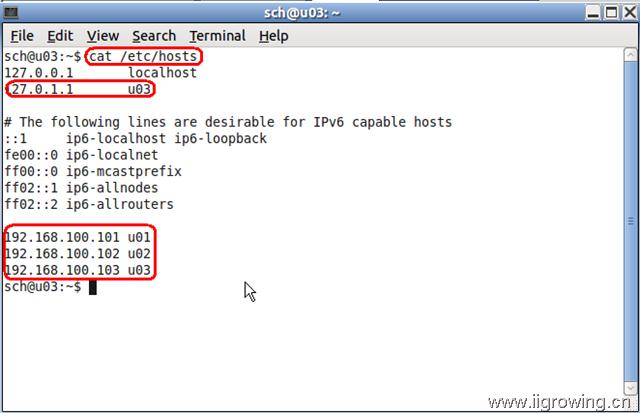
我们三台虚拟机ip及用户及密码如下
机器名称
Ip地址
用户/密码
u01
192.168.100.101
sch/sch root/root
u02
192.168.100.102
sch/sch root/root
u03
192.168.100.103
sch/sch root/root
测试网络连接情况
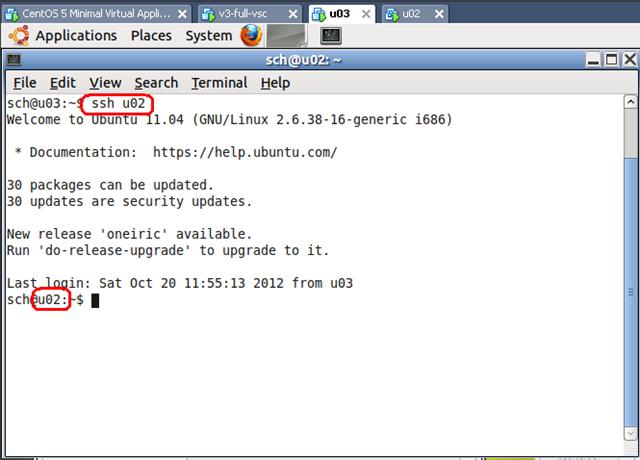
如上图,输入 ssh u02 之后显示上面图像,则表明配置已经成功
类似,ssh u01
从新发布一下,虚拟机及参考视频下载地址
虚拟机文件,地址如下:
hadoop.0.1.0.part02.rar (700.00M, 2012年11月21日 00:19 到期)
hadoop.0.1.0.part01.rar (700.00M, 2012年11月21日 00:19 到期)
hadoop.0.1.0.part04.rar (313.02M, 2012年11月21日 00:16 到期)
hadoop.0.1.0.part03.rar (700.00M, 2012年11月21日 00:16 到期)
虚拟机配置参考视频
hadoop-vmware-0.1.0-www.iigrowing.cn.rar (37.26M, 2012年11月29日 10:33 到期)
hadoop 的 eclipse项目创建过程
hadoop-0.1.0-java-project.rar (50.17M, 2012年11月29日 10:33 到期)
参考文章
Hadoop源代码分析 之Datanode工作原理(5)—–拷贝文件过程总结
Hadoop源代码分析 之Datanode工作原理(4)—–拷贝本地文件到hadoop的过程
Hadoop源代码分析 之Datanode工作原理(3)—–datanode工作过程总结
Hadoop源代码分析 之Datanode工作原理(2)—–datanode基本工作过程
Hadoop源代码分析 之Datanode工作原理(1)—–datanode启动过程代码分析
Hadoop源代码分析 之hadoop配置及启动(4)—–启动过程汇总
Hadoop源代码分析 之hadoop配置及启动(3)—–classpath与hadoop主要组件启动过程
Hadoop源代码分析 之hadoop配置及启动(2)—–classpath与启动shell脚本
Hadoop源代码分析 之hadoop配置及启动(1)—–classpath与配置文件
Hadoop源代码分析 之hadoop源代码项目(1)—–创建eclipse下java项目
Hadoop源代码分析 之环境配置(1)—–hadoop虚拟机配置
Hadoop源代码分析 之概念介绍(2)—–初学者眼中的hadoop



